-
호가창 정보 가져오기금융 2023. 1. 26. 12:17728x90
호가창을 보며 실시간 걸래를 하는 분들이 많다고 한다. (단타/초단타)
이를 자동화 하기 위해, 호가창을 logging하는 부분을 구현해보았다.
주식 API를 쓰는건 불편함이 많기에... (예전에 만들어진 api 그대로 유지되는 부분이 많아 좋지 않다 생각...)
좋아보이는 web site를 하나 parsing하기로 하였다.
(미안해요 KB)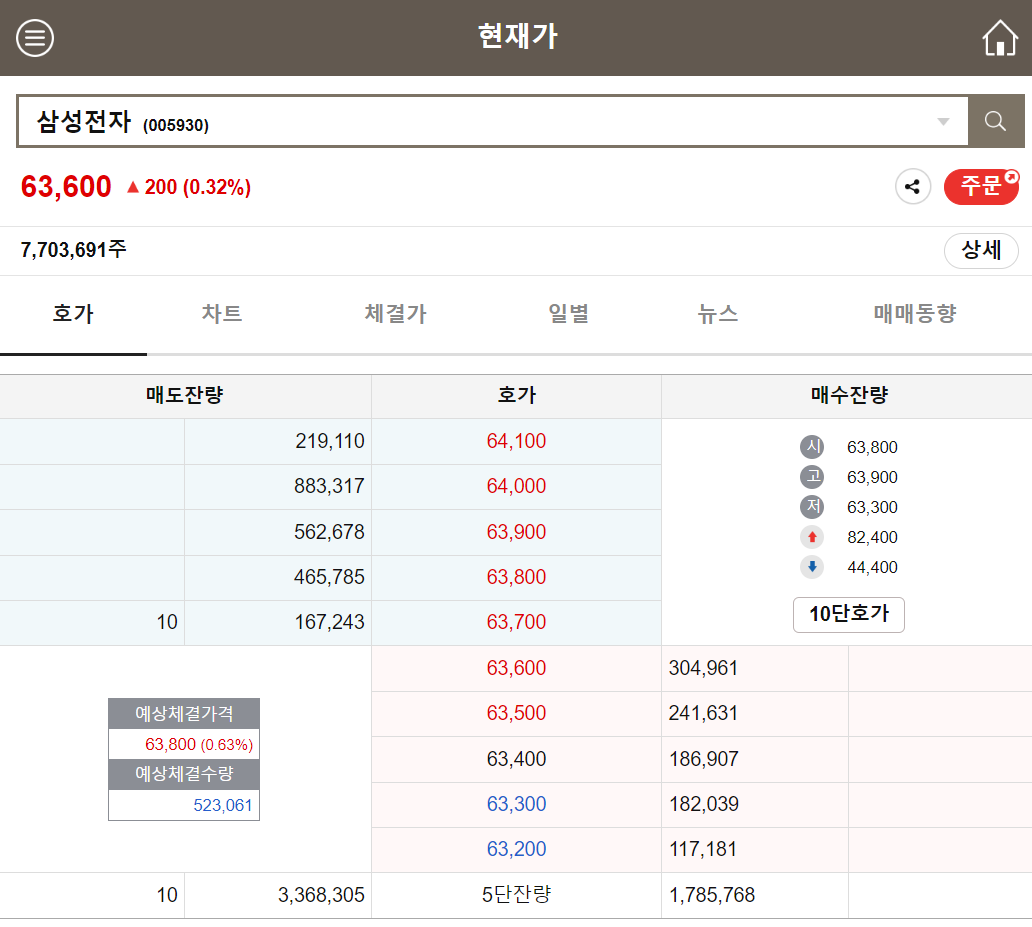
KB 증권 모바일 창 위의 창에서 실시간 호가 / 각 호가의 잔량을 logging하는 코드를 아래와 같이 구현하였다.
import datetime from bs4 import BeautifulSoup as BS import pandas as pd from selenium import webdriver from selenium.webdriver.common.by import By import time import threading global flag class kb_loader: # kb 증권에서 data를 읽어오는 class # input: 종목코드, sampling time (sampling 주기), file_name (저장용) def __init__(self, 종목코드:str, sampling_time= 1,file_name = ""): self.code = 종목코드 self.url = 'https://m.kbsec.com/go.able?linkcd=m04010000&flag=0&JmGb=Q&stockcode='+self.code self.호가_10lev = True # 10단 호가를 켤지 여부. if self.호가_10lev: self.매도잔량 = ['0' for i in range(10)] self.매도호가 = ['0' for i in range(10)] self.매수잔량 = ['0' for i in range(10)] self.매수호가 = ['0' for i in range(10)] else: self.매도잔량 = ['0' for i in range(5)] self.매도호가 = ['0' for i in range(5)] self.매수잔량 = ['0' for i in range(5)] self.매수호가 = ['0' for i in range(5)] self.data = "" self.현재가 = 0 self.sampling_time = sampling_time print(self.code + " loader created") # 옵션 생성 options = webdriver.ChromeOptions() # 창 숨기는 옵션 추가 options.add_argument("headless") self.driver = webdriver.Chrome('chromedriver',options=options) self.driver.get(self.url) if self.호가_10lev: try: button=self.driver.find_element(By.XPATH,'//a[@href="javascript:show10dan();"]') # 매수총잔량 button.click() except: print("not clickable") self.file_name = file_name def __del__(self): # class 종료 함수 try : self.driver.close() except: print("already closed") print(self.code + " loader finished") def logging(self): while(True): global flag res_text = self.driver.page_source parsed_res_text = BS(res_text, 'html.parser') self.parsing_kb(parsed_res_text) # parsing해서 self.create_data() # dataframe으로 저장 if flag == False: break time.sleep(self.sampling_time) def create_data(self): temp_time = datetime.datetime.now() temp_t = str(temp_time.hour * 3600 + temp_time.minute * 60 + temp_time.second) temp_data=[self.현재가]+[i for i in self.매도잔량] +[i for i in reversed(self.매수잔량)] if type(self.data)==str: # 첫 데이터 self.data=pd.DataFrame({temp_t:temp_data}) # print(self.data) else: self.temp_data = pd.DataFrame({temp_t: temp_data}) self.data = pd.concat([self.data,self.temp_data],axis=1) # print(self.data) def save_data(self): print("save data") print(self.data) t=datetime.datetime.now() t=t.hour *3600 + t.minute*60 + t.second self.data.to_csv(self.file_name+self.code+"_"+str(t) + '.csv', encoding="euc-kr") def parsing_kb(self, parsed_res_text): temp=parsed_res_text.find("div", attrs={"name":"fid_price"}) temp = temp.text.replace(",","").split(" ") temp_현재가 =int(temp[0].split("(")[0]) if (temp_현재가 > self.현재가 *2) and (self.현재가 !=0): # 첫 데이터가 아니면서, 현재가가 과하게 뛴 경우 (숫자가 0이 더 붙는 경우가 발생하는 경우 예외처리) print("현재가 parsing error") print(temp[0]) print("한 자리 제거") elif (temp_현재가==0): print("현재가 0 버그. 기존값 유지") else: self.현재가=int(temp[0].split("(")[0]) if self.호가_10lev: tables = parsed_res_text.find("table", attrs={'class' : 'hTy3 bTy2'}) else: tables = parsed_res_text.find("table", attrs={'class': 'hTy2 bTy2'}) # for i in tables: # tables_re = tables[1].find_all("tr") # for index, i in enumerate(tables_re): # if index > 0: i=tables if self.호가_10lev: num_호가 = 10 for temp_index in range(1, num_호가+1): temp = i.find('td', attrs={'class': "tR cellTy1", 'name': 'fid_sAskprcRv' + str(temp_index)}) if temp != None: self.매도잔량[temp_index - 1] = temp.text temp = i.find('span', attrs={'name': 'fid_sAskprc' + str(temp_index)}) if temp != None: self.매도호가[temp_index - 1] = temp.text temp = i.find('td', attrs={'class': "tL cellTy2", 'name': 'fid_bAskprcRv' + str(temp_index)}) if temp != None: self.매수잔량[temp_index - 1] = temp.text temp = i.find('span', attrs={'name': 'fid_bAskprc' + str(temp_index)}) if temp != None: self.매수호가[temp_index - 1] = temp.text else: num_호가 = 5 for temp_index in range(1, num_호가+1): temp = i.find('td', attrs={'class': "tR cellTy1", 'name': 'fid_sAskprcRv' + str(temp_index)}) if temp != None: self.매도잔량[temp_index - 1] = temp.text temp = i.find('span', attrs={'name': 'fid_sAskprc' + str(temp_index)}) if temp != None: self.매도호가[temp_index - 1] = temp.text temp = i.find('td', attrs={'class': "tL cellTy2", 'name': 'fid_bAskprcRv' + str(temp_index)}) if temp != None: self.매수잔량[temp_index - 1] = temp.text temp = i.find('span', attrs={'name': 'fid_bAskprc' + str(temp_index)}) if temp != None: self.매수호가[temp_index - 1] = temp.text if __name__ == "__main__": global flag m_loader=kb_loader('005930', 1, '삼성전자_') # 삼성전자 data를 test함 flag =True thread = threading.Thread(target=m_loader.logging) # 실시간 logging을 별도의 thread로 돌림 thread.start() time.sleep(60)# 60초 후 종료 flag=False m_loader.save_data() del(thread)길긴 하지만... 위의 kb_loader 클래스만 갖다 쓰면 된다.
그리고 별도의 thread로 쪼개서 구현하였다. (main에서 해당 class를 제어)
* 돌리기 위해선 chromedriver를 해당 경로에 넣어야한다. (참고:https://engineerer.tistory.com/10)
결과 저장은 아래와 같은 형태로 되게 하였다.
물론 kb_loader.data에는 실시간 data가 들어가고 있다.
 728x90
728x90'금융' 카테고리의 다른 글
HTML Tag 공부 web page (0) 2023.01.26 주식 등락률 상위 종목 로그 (0) 2023.01.25 네이버 증권 등락률 의미 (0) 2023.01.24 키움 api 비밀번호 종류 (0) 2023.01.18 오전 9시 주식 단타, 정말 다를까? (2) 2022.12.10